Web Architecture 101


Dưới đây là một số ghi chép của mình trong quá trình tìm hiểu về scaling hệ thống.
Trước khi nói về việc hệ thống có thể phục vụ được bao nhiêu "triệu" người, mình quan tâm đến việc hệ thống hiện tại đã chạy đúng chưa, có những thành phần nào, bảo mật bằng phương thức nào, sử dụng database gì...
Những câu hỏi trên khi phỏng vấn người ta có thể test mình bằng cách hỏi một câu: Khi người dùng nhập địa chỉ trang web của bạn vào ô tìm kiếm trên Google, điều gì sẽ xảy ra?
Như có đề cập trong sách Cracking the coding interview, việc mình đưa ra một số giả định ban đầu rồi từ từ mở rộng ra là cách trả lời khá hay, giúp mình không bị overload quá nhiều ngay từ lúc đầu. Điều này mình thấy cũng đúng trong quá trình implement thực tế, khi hệ thống còn bé, chúng ta quan tâm đến việc hệ thống chạy đúng, cũng như hiểu rõ những công nghệ đang dùng.
I. Single Server setup
Giả sử mọi thứ ban đầu đều chạy trên một server duy nhất. Khi đó, web app và mobile app của chúng ta sẽ kết nối với web server để hiển thị dữ liệu có trong database ; ngoài ra có thể có caching.
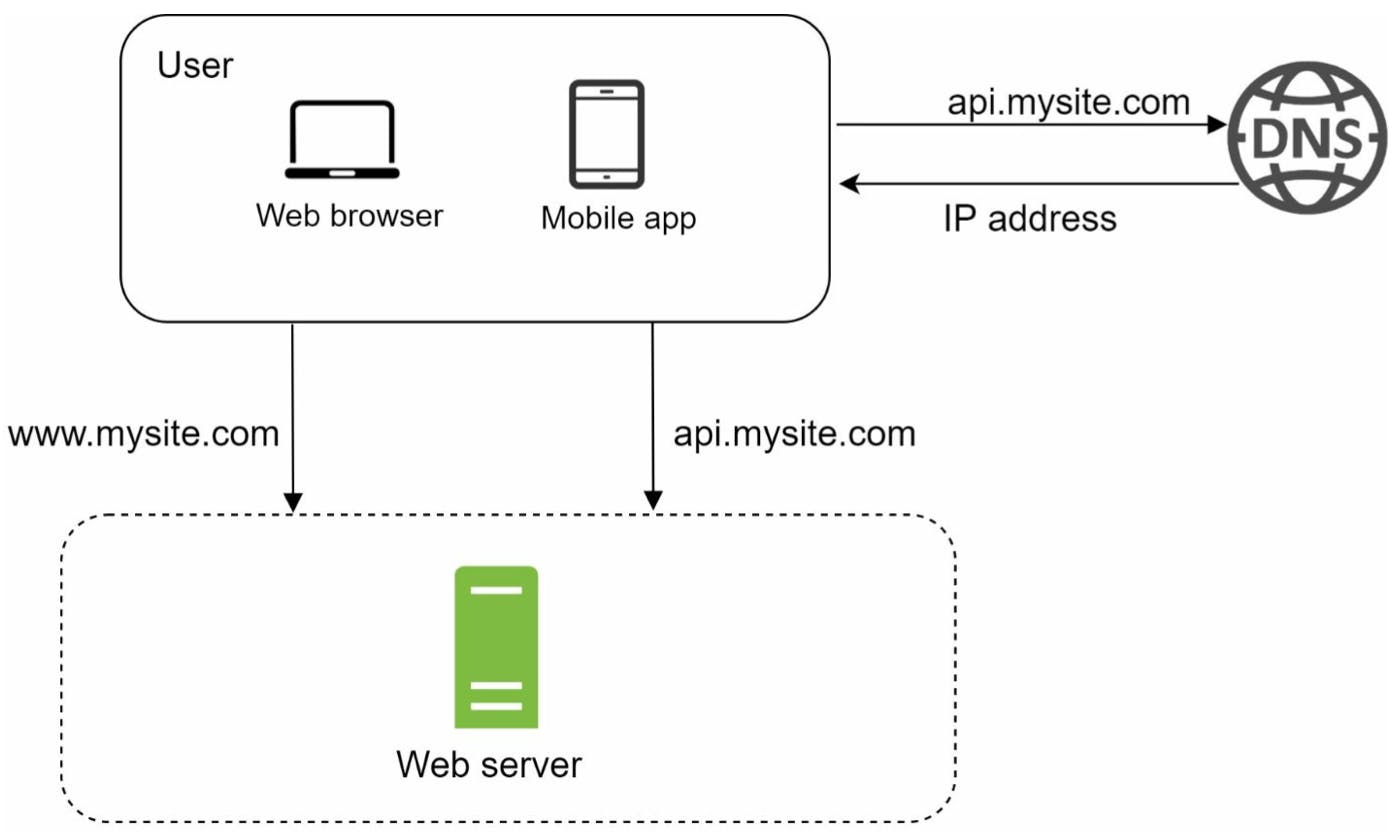
Người dùng truy cập trang web của mình bằng cách gõ tên miền (domain name) vào ô tìm kiếm của google rồi ấn Enter. Domain Name System (DNS) là một service trả phí của bên thứ 3 và service này không được hosted trên server của mình. Khi đó DNS sẽ trả về một địa chỉ IP tương ứng với domain name này.
Khi nhận được địa chỉ IP, một HTTP request sẽ được gửi trực tiếp từ web/mobile app đến web server. Có thể kèm theo một số headers.
Web server sẽ trả về HTML pages để render ra trên phía client hoặc JSON object để client render.
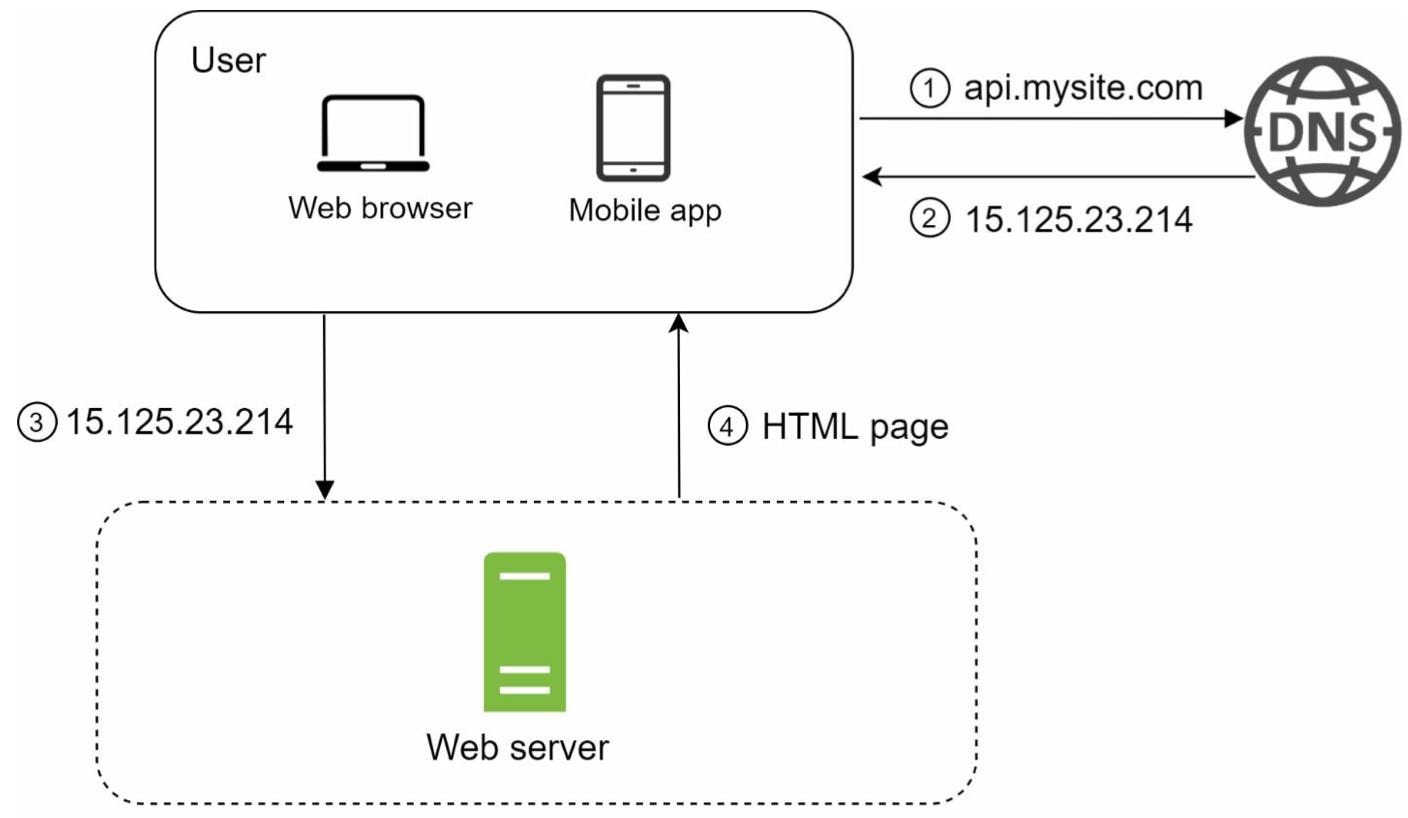
Cụ thể hơn, mình cần hiểu rõ về các loại traffic source, tức là dữ liệu gửi đi và trả về sẽ có những gì. Có thể chia traffic source đến web server của mình thành hai loại: traffic đến từ web app và traffic đến từ mobile app.
Web application: sử dụng HTML và JavaScript cho phần presentation và có thể dùng những ngôn ngữ server-side để handle một số business logic (Java, Python, ...)
Mobile application: có thể viết bằng cross-platform hoặc native.
Thường format dữ liệu trả về từ các API là dạng JavaScript Object Notation (JSON) vì tính trực quan, đơn giản.
{
"id": 12,
"first_name": "John",
"last_name": "Doe",
"address": "21 2nd Street",
"hobby": [
"apple",
"samsung",
"huawei
]
}
II. Database
Một thành phần không thể thiếu với hầu hết các hệ thống là Database. Vì hầu hết các web và mobile hiện nay đều cần dynamic content, việc đọc/ghi dữ liệu diễn ra thường xuyên chứ không chỉ là các html tĩnh.
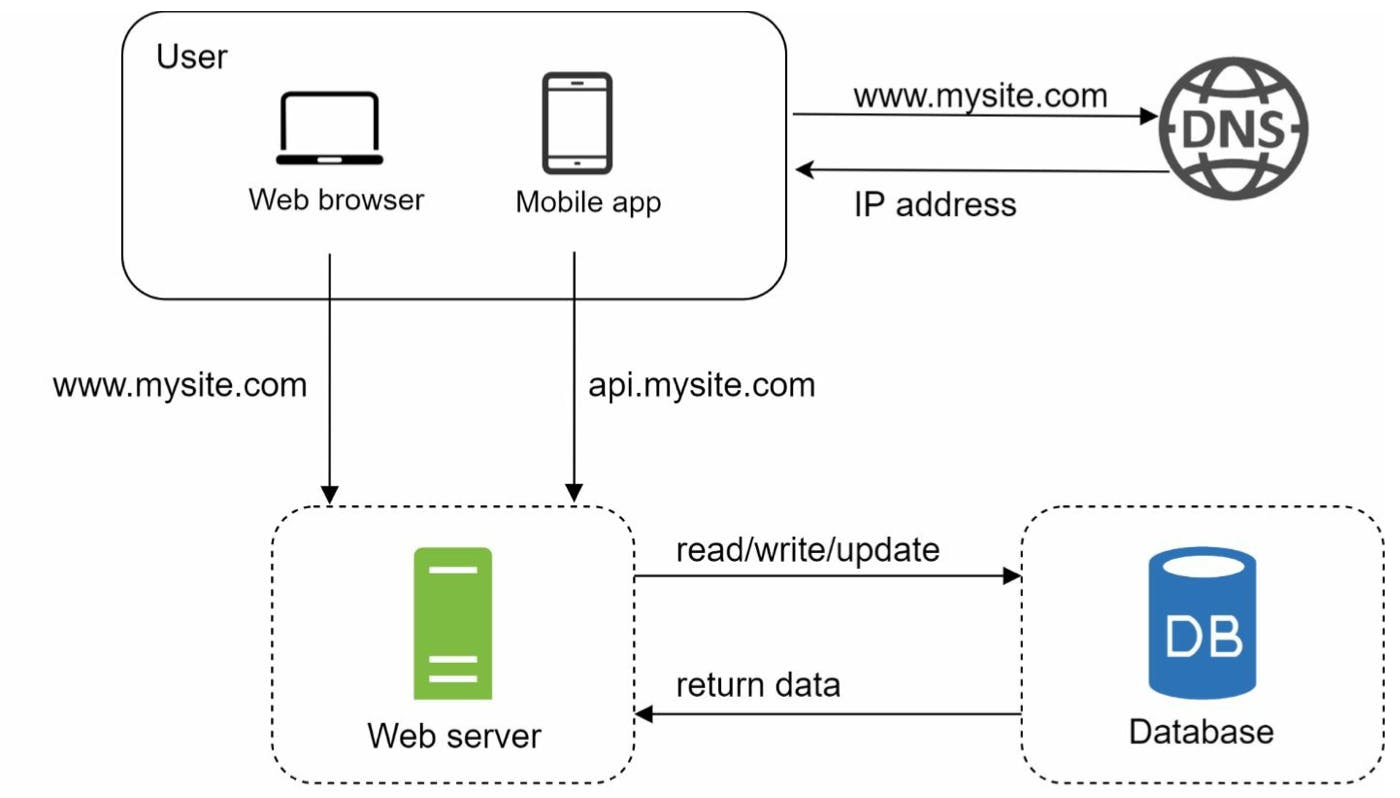
Như mình có nói ở đầu, việc chọn lựa database như thế nào là vấn đề cần quan tâm trước khi nghĩ đến việc scaling.
Hiện nay RDBMS - Hệ quản trị cơ sở dữ liệu dạng quan hệ hoặc SQL database là được dùng nhiều nhất. Một số ví dụ như PostgreSQL, MySQL, Oracle database, etc. Những dạng này lưu data trong bảng. Join operation thường được dùng khi mình cần sử dụng dữ liệu ở nhiều bảng khác nhau.
Ngoài ra còn có NoSQL database như MongoDB, Neo4j, Cassandra, DynamoDB, etc. Những dạng này thường được chia vào một trong 4 nhóm: key-value store, graph store, column store, và document store. Mình chưa sử dụng hết tất cả các loại này, chỉ biết Neo4j lad graph store và MongoDB là document store. Sẽ có bài chi tiết trong tương lai. Join operations cũng không được support trong non-relational databases.
Non-relational database có thể được dùng cho các mục đích:
App yêu cầu độ latency super-low
Data của mình là unstructured, không thể cấu hình theo một dạng schema chung như SQL database,
Data của mình ko có relational data (JSON, XML, YAML, etc.)
Số lượng lưu trữ là rất lớn
Như vậy, một hệ thống đơn giản bao gồm những thành phần mình đã bàn ở trên. Trong hệ thống này, users connect trực tiếp tới web server. Nếu web server sập, offline thì users sẽ không thể kết nối được. Trong một viễn cảnh khác, khi server của mình đạt ngưỡng load's limit, user cũng sẽ nhận được response trả về chậm hơn hoặc fail connect. Khi đó mình bắt đầu nghĩ đến việc scale hệ thống.
III. Vertical scaling vs. Horizontal scaling
Vertical scaling là việc mình scale up server của mình. Cụ thể là mình sẽ tăng thêm core cho CPU, thêm dung lượng RAM lớn hơn, etc. Horizontal scaling là việc scale server bằng cách đặt thêm nhiều server vào trong hệ thống của mình.
Khi traffic bị chậm, việc suy nghĩ đến vertical scaling là một giải pháp khả thi. Tăng sức mạnh phần cứng sẽ giúp tăng tốc độ xử lý và response của server. Đây là một giải pháp thiên về tính vật lý, và nó cũng có một số nhược điểm:
Dung lượng RAM, số luồng xử lí CPU, ... là không thể tăng mãi.
Việc scaling theo hướng vertical vẫn gặp sự cố khi server chết, khi đó dữ liệu sẽ không được backup sang các node khác.
Horizontal scaling thường được dùng nhiều hơn ở các hệ thống lớn vì nó giải quyết được 2 khuyết điểm trên của vertical scaling.
IV. Load balancer
Khi mình có nhiều web server trong hệ thống, load balancer sẽ đảm nhiệm việc gửi request từ client đến một trong các web server.
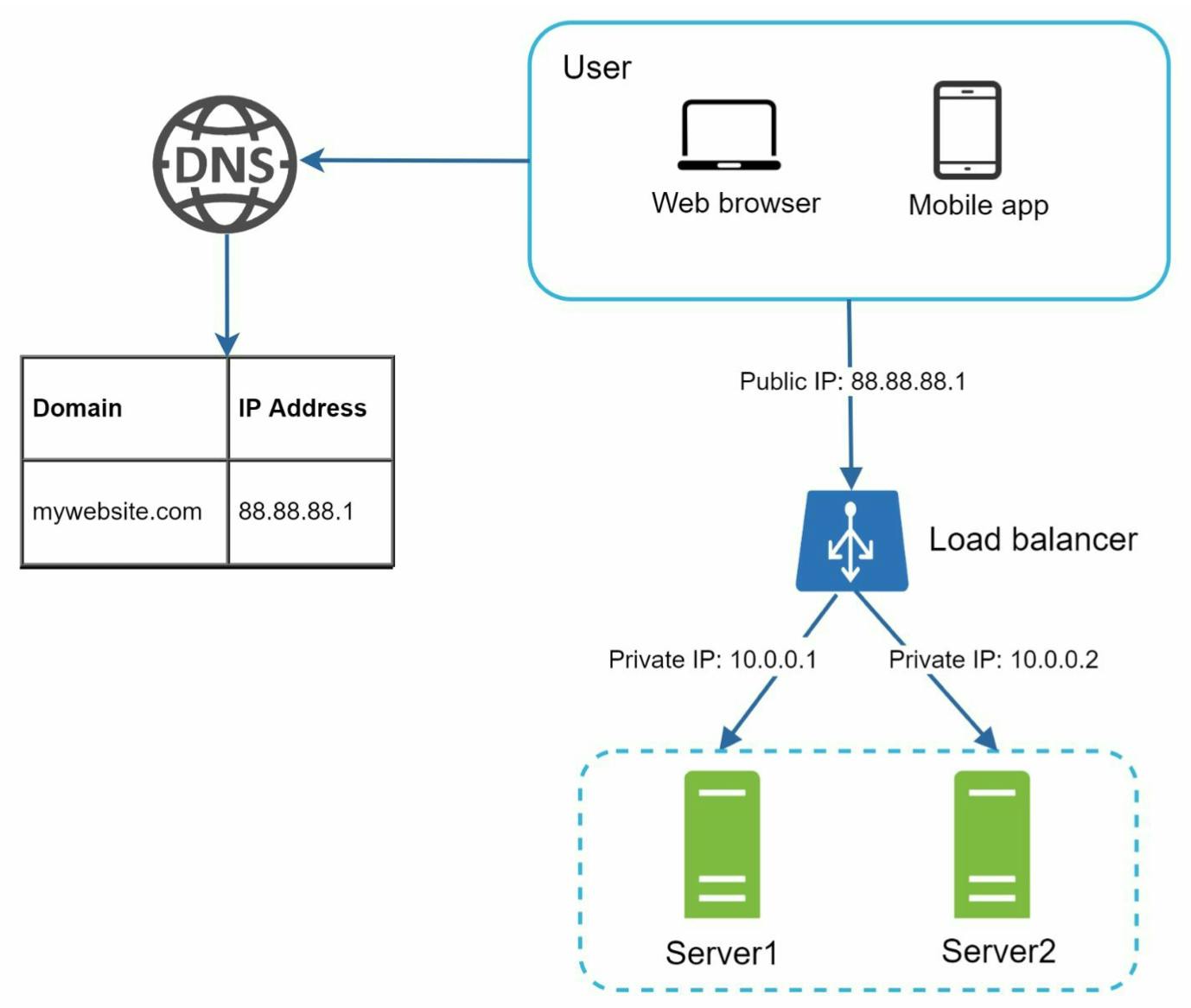
Bây giờ, users không còn connect trực tiếp với IP của web server nữa, thay vào đó là IP public của load balancer. Khi đó, các IP của web servers sẽ là private IPs, những IP này chỉ reachable giữa các server dùng chung mạng cục bộ, không phải over the internet như lúc đầu.
Việc đưa request từ client (mỗi client sẽ có IP address phân biệt) đến server nào được load balancer định nghĩa trong load-balanced set.
Việc sử dụng load balancer giúp mình giải quyết được bài toán cân bằng tải tức giảm số lượng request tới một server đồng thời khắc phục sự cố chết một server nào đó. Ví dụ như trong hình trên, ta có 2 servers:
Khi server 1 offline, tất cả traffic sẽ được routed đến server 2. Điều này giúp ngăn ngừa việc website sập khi 1 server nào đó offline. Mình sẽ tạo một web server mới vào server pool và cho load balancer trỏ tới như bình thường.
Khi traffic nhiều lên, 2 servers không đủ handle, mình sẽ tạo thêm các servers mới vào server pool và load balancer tự động send những request tới chúng.
Như vậy, việc add load balancer vào web tier giúp hệ thống scale tốt hơn. Còn database tier thì sao?
V. Database replication
Theo wikipedia định nghĩa: "Database replication can be used in many database management systems, usually with a master/slave relationship between the original (master) and the copies (slaves)".
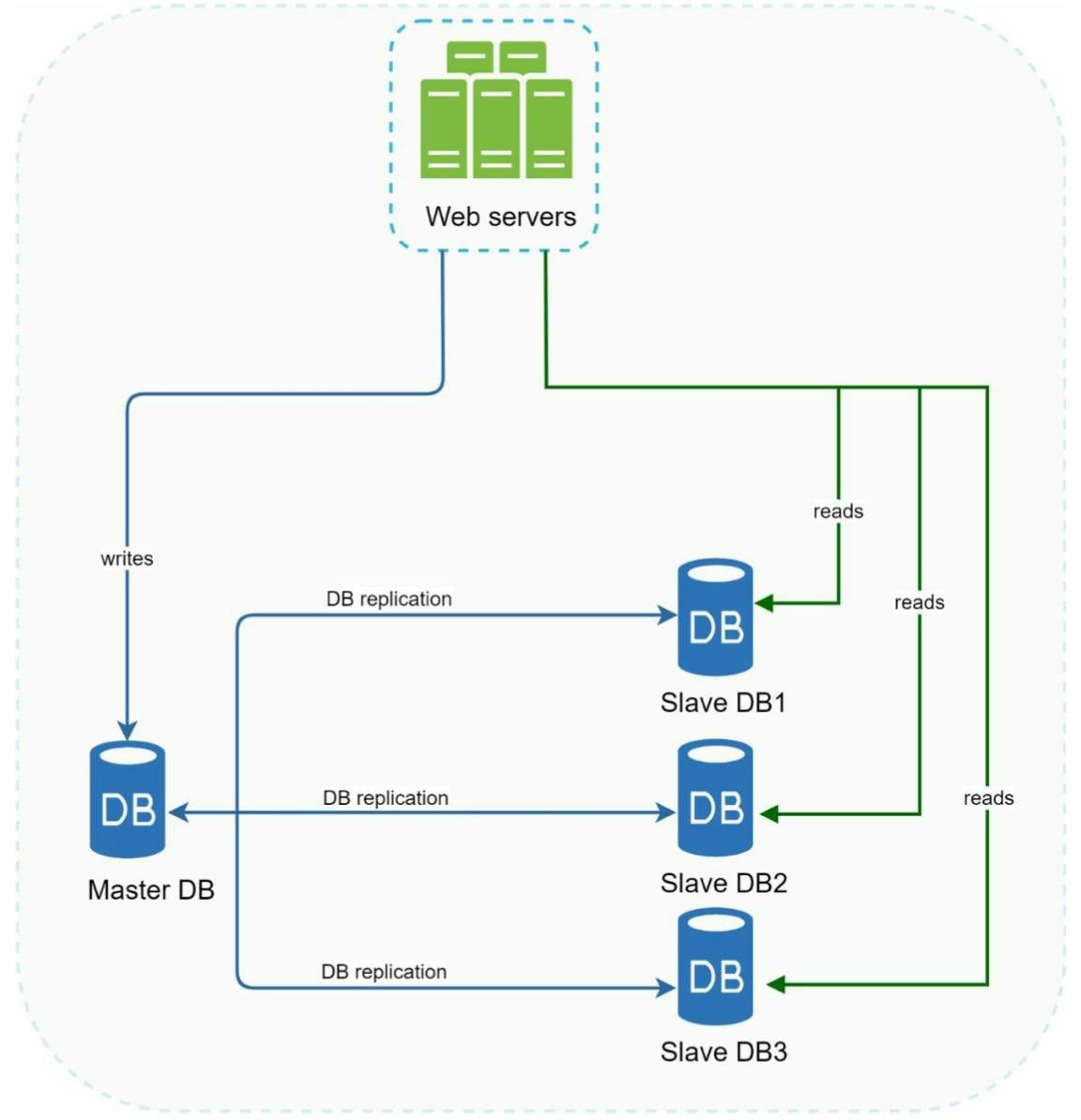
Master database thường được dùng cho các tác vụ ghi (write). Slave database copy data từ master database và thường được dùng cho các tác vụ đọc (read). Những tác vụ khác liên quan đến việc data-modifying như insert, delete, update phải được gửi đến master database.
Trên thực tế các app thường có tỉ lệ \(\dfrac{read}{write} \geq 1\) nên có thể ta cần số lượng các slave database nhiều hơn master database.
Cũng giống như việc có load balancer ở web tier, database replication có một số ưu điểm sau:
Performance tốt hơn: master-slave model có sự phân chia giữa các tasks read và write nên nó cho phép các queries được thực hiện song song nhiều hơn
Reliability: Nếu một database server gặp sự cố, data của mình cũng không bị mất đi vì data được replicated ở nhiều location khác nhau.
Việc 1 server database offline hơi khác so với trường hợp của load balancer một chút:
Khi server offline là slave: các tác vụ read sẽ được directed đến master database. Một slave mới sẽ được tạo ra để thay thế slave cũ. Khi tất cả các slave sẵn sàng, các tác vụ read sẽ được redirected lại các slave.
Khi server offline là master: một trong số các slave database sẽ được đưa lên để thay thế cho master. Tất cả các tác vụ tạm thời được thực hiện trên master mới này. Đồng thời một slave mới cũng được tạo ra để thay cho slave cũ. Trong thực tế, việc thăng cấp một slave database lên master database tốn công sức hơn vì dữ liệu trong slave và master cũ có thể không trùng nhau do chưa kịp update. Khi đó, mình có một số cách giải quyết như chạy script recovery, sử dụng những model khác như multi-master, circular replication ...
Bây giờ, hệ thống của mình có thể được hình dung như hình dưới:
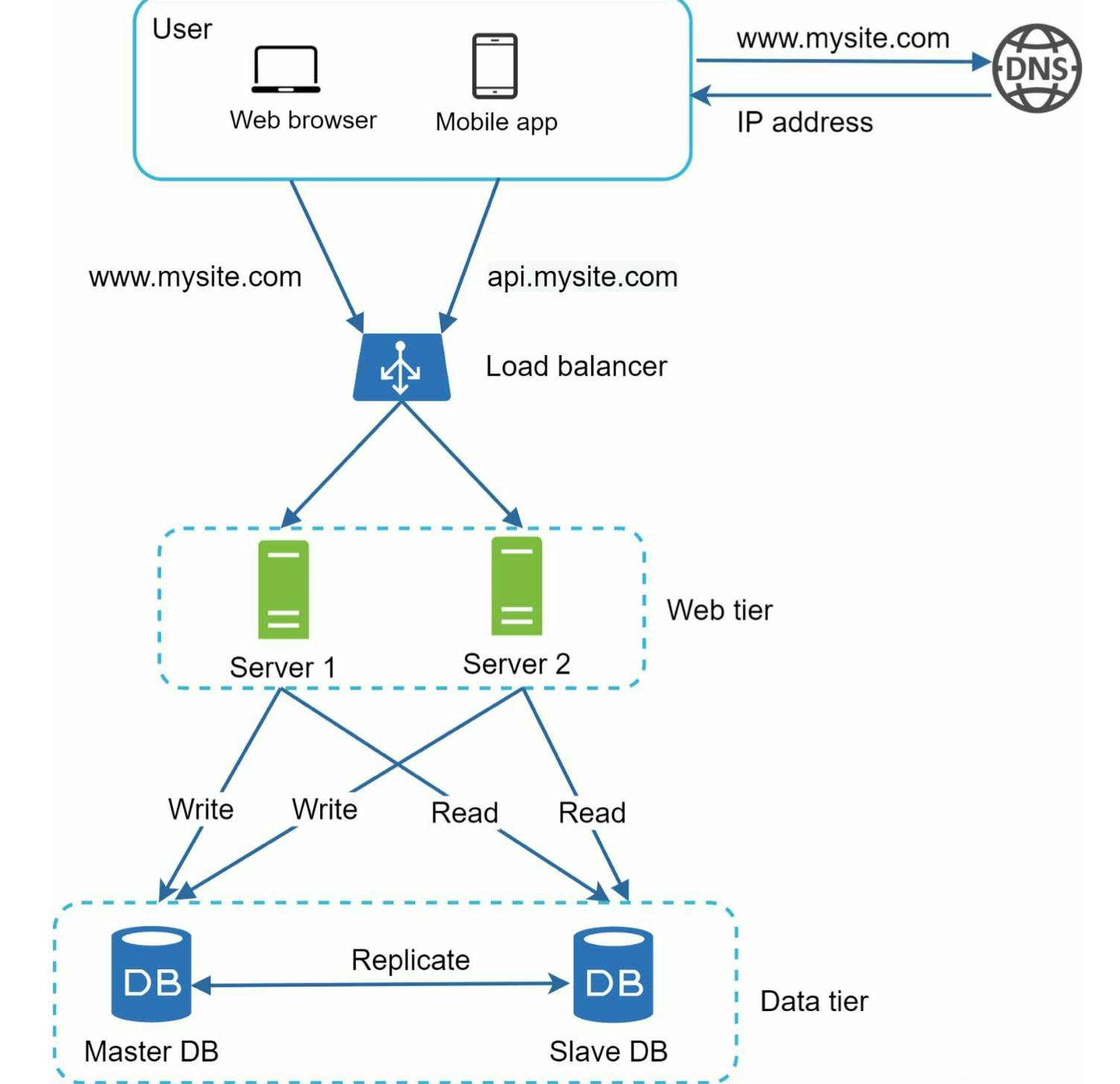
User lấy IP address của load balancer thay vì web server trong DNS
User connect tới load balancer bằng IP vừa nhận được
HTTP request sẽ được routed tới server 1, hoặc 2, ...
Web server sẽ đọc user data từ slave database
Web server route các tác vụ data-modifying tới master database (write, update, delete)
Ngoài data của user, hệ thống có thể còn chứa rất nhiều loại data khác, ví dụ như file ảnh, code javascript, css, video, ... Khi đó, cache layer và content delivery network (CDN) sẽ giúp cho thời gian request/response của hệ thống được nhanh hơn.
VI. Cache
Cache là một định nghĩa về không gian lưu trữ dữ liệu nhưng khác database là dữ liệu được lưu trữ trong cache là result của các response nặng, những data thường xuyên được accessed và được đặt ở trước database server để rút ngắn thời gian serving các request tiếp theo.

Khi nhận request gửi từ phía client, web server sẽ kiểm tra trong cache có response cần trả về hay không. Nếu cache có, data sẽ được gửi từ cache tới web server rồi đến client. Nếu trong cache không có, nó sẽ queries từ database và lưu lại trong cache sau đó tiếp tục gửi về client. Strategy này được gọi là read-through-cache.
Một số lưu ý khi sử dụng cache:
Cache thường được dùng cho những hệ thống mà việc đọc data xảy ra thường xuyên và ghi data xảy ra ít. Cache không phải là nơi để lưu trữ dữ liệu vì khi cache server restart, toàn bộ dữ liệu trước đó sẽ bị mất.
Expiration: dữ liệu được lưu trong cache cần có thời hạn nhất định tránh bị quá cũ. Expiration cũng không nên quá ngắn vì có thể phản tác dụng của cache khi cache phải queries xuống database nhiều lần.
Consistency: Việc ghi, update dữ liệu mới vào database có thể dẫn đến inconsistence với dữ liệu lưu trong cache.
Giống như bài toán web server, hệ thống có 1 cache server duy nhất cũng có thể dẫn đến việc toàn bộ hệ thống bị ảnh hưởng nếu cache server offline (đây là một dạng SPOF - single point of failure). Một giải pháp thường được khuyên là sử dụng multi-cache server cho các data center (được nói đến phía dưới) khác nhau. Hoặc có một giải pháp khác gọi là over provisioning luôn có một phần dư ra trong bộ nhớ để đảm bảo việc ghi dữ liệu diễn ra bình thường.
Eviction policy: khi bộ nhớ trong cache bị đầy, có thể một số dữ liệu đang lưu bị xóa. Least-recently-used (LRU) là policy thường dùng nhất để giải quyết các trường hợp này. Ngoài ra còn có một số policy khác như Least Frequently Used (LFU - ưu tiên dữ liệu dùng thường xuyên), First in First Out (FIFO)...
VII. Content Delivery Network (CDN)
CDN là một server dùng để deliver những static content trong hệ thống. CDN server sẽ cache những content dạng JavaScript, images, CSS, videos, ...
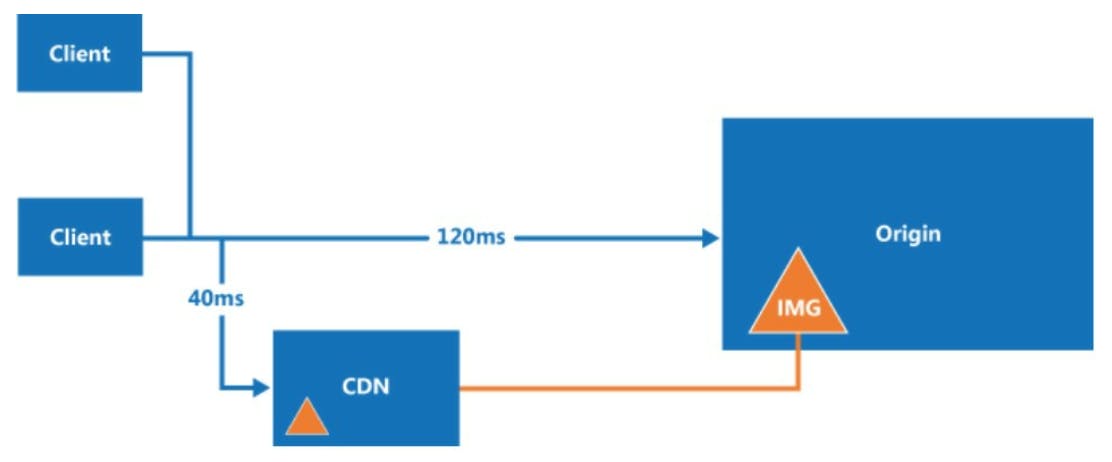
Hình dưới minh họa cách thức hoạt động của CDN:
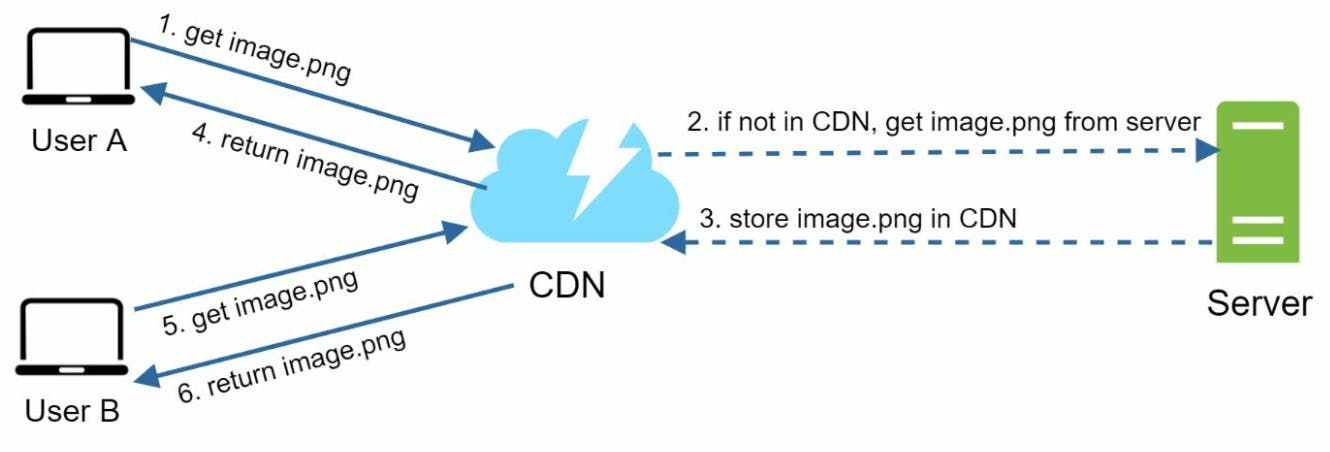
User A cần image.png bằng cách sử dụng image URL. URL này của image được cung cấp bởi CDN provider ví dụ như mysite.cloudfront.net/logo.jpg của Amazon.
Tương tự cache, nếu CDN server không có image.png, CDN server gửi request đến nơi lưu file gốc, nơi này có thể là database hoặc một dịch vụ lưu trữ online như Amazon S3 storage.
image.png được trả về thành công sẽ kèm theo HTTP header Time-to-live (TTL) cho biết thời gian image đó được cache.
CDN cache image này và return nó đến user A.
User B gửi request tới cùng image.png như A
Image sẽ được return ngay bởi CDN nếu còn trong thời gian TTL
Như vậy, sau khi có thêm CDN và cache, hệ thống của mình sẽ trông như sau:
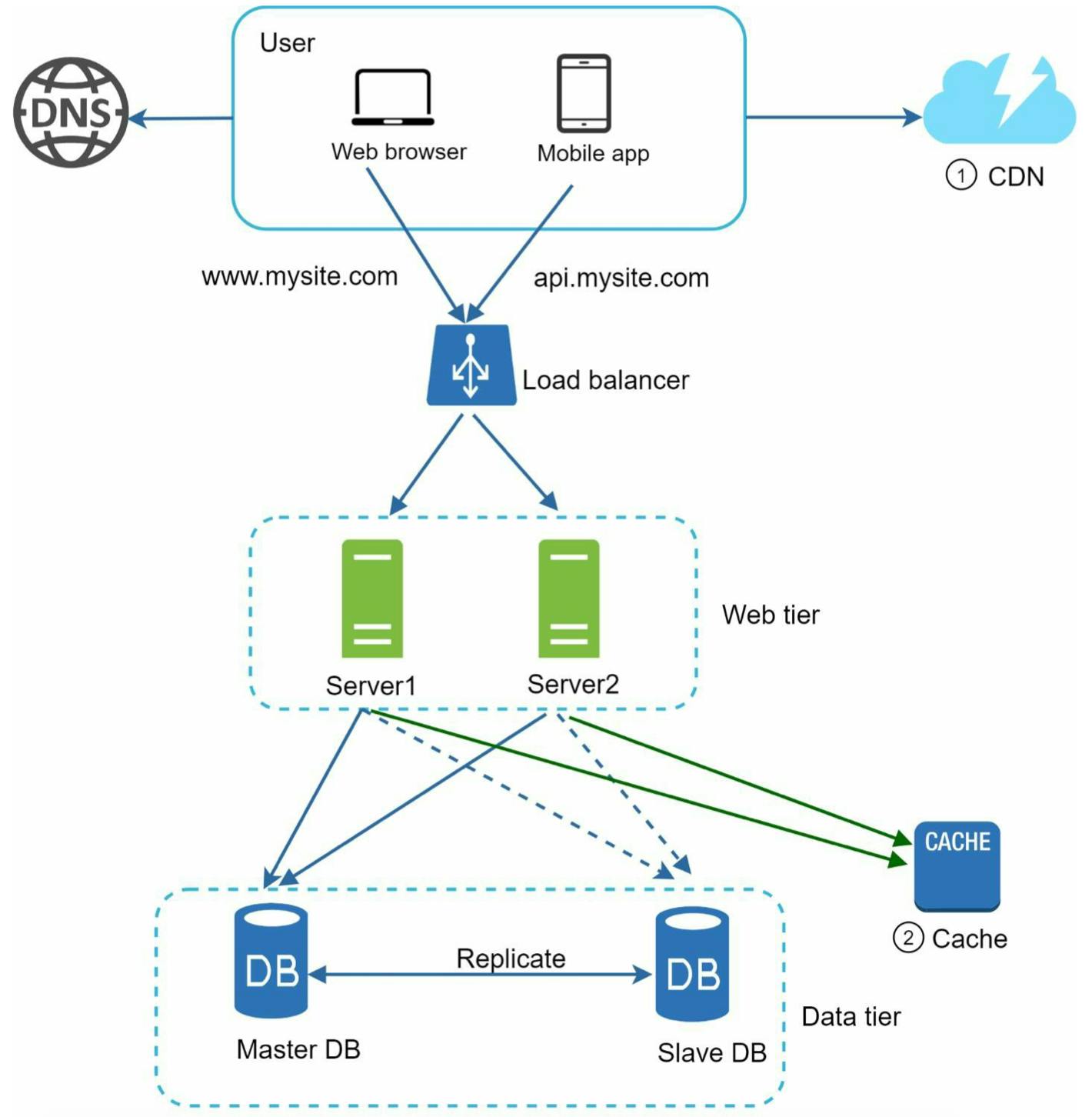
Static assets (như JS, CSS, images, ...) không còn được served bởi web server, thay vào đó là được fetched từ CDN để cho performance tốt hơn
Việc truy vấn xuống database cũng được giảm tải với cache.
VIII. Stateless vs. Stateful architecture
Good practice ở đây là mình nên move state (ví dụ như session đăng nhập của user, ...) ra khỏi web tier (stateless). Có thể lưu những state này vào trong no-sql database như MongoDB. Ngược lại, stateful tier sẽ ghi nhớ các client data từ các request.
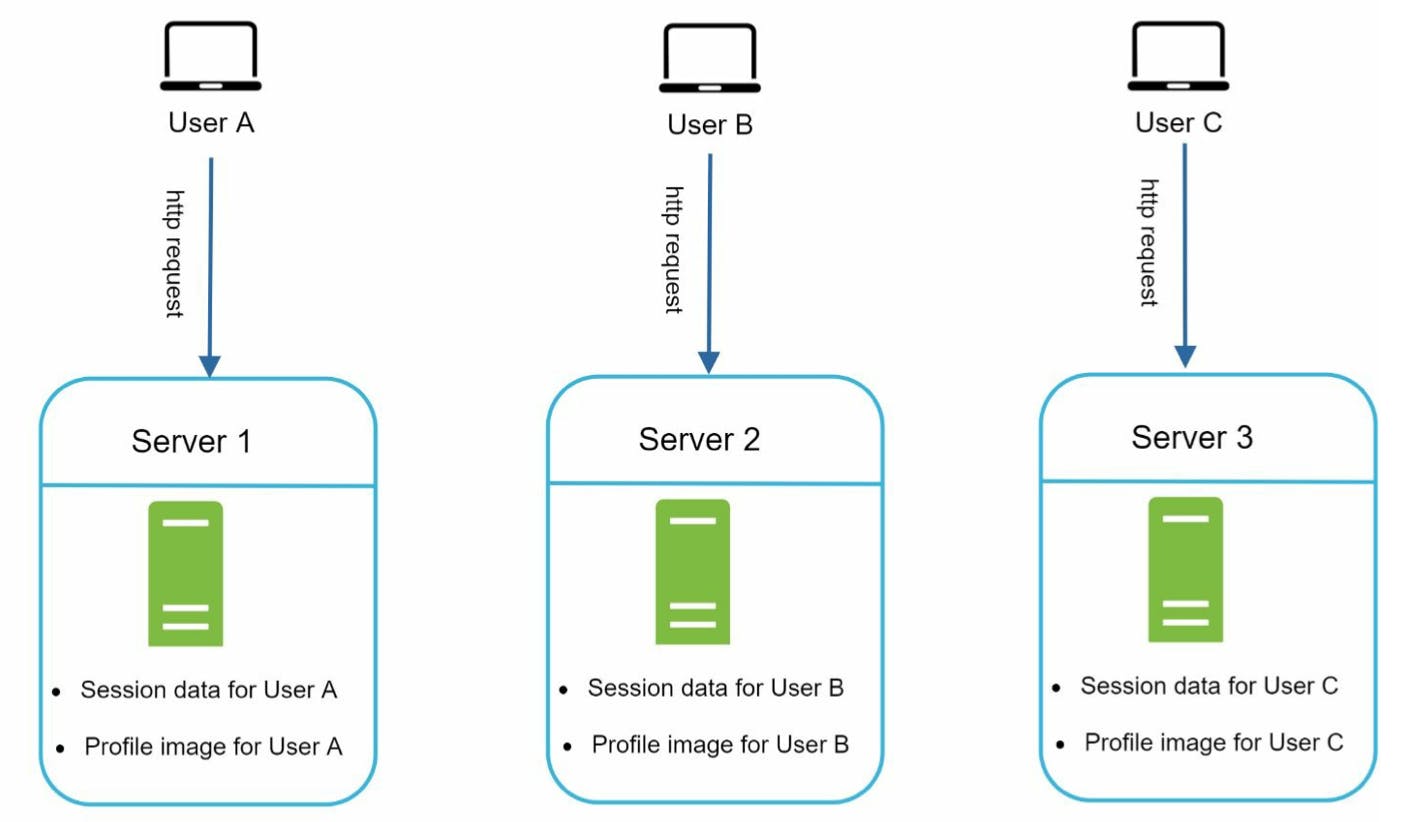
Do mỗi server ghi nhớ state của người dùng nên HTTP request từ người dùng A (trong hình trên) phải được rounted tới server 1, nếu request này gửi tới các server khác (không chứa thông tin người dùng A), việc authenticate sẽ bị failed. Tương tự như vậy với các người dùng B, C, ...
Trong stateless architecture, tất cả HTTP requests từ users có thể được gửi đến bất kì server nào, data của user sẽ được fetch từ một shared data store (có thể là MongoDB).
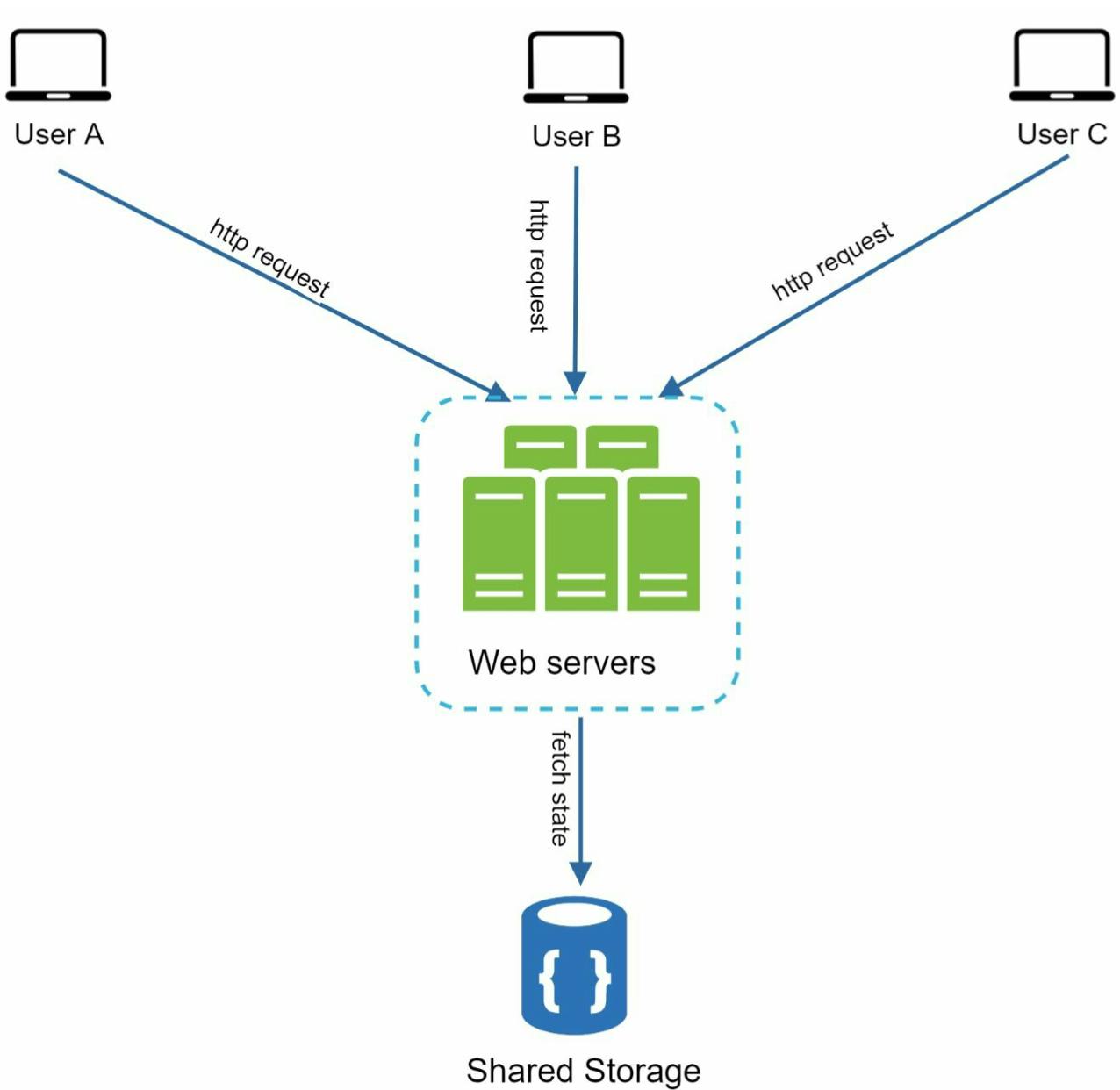
Sau khi update thiết kế dạng stateless cho web tier, hệ thống mình bây giờ có thể hình dung như sau:
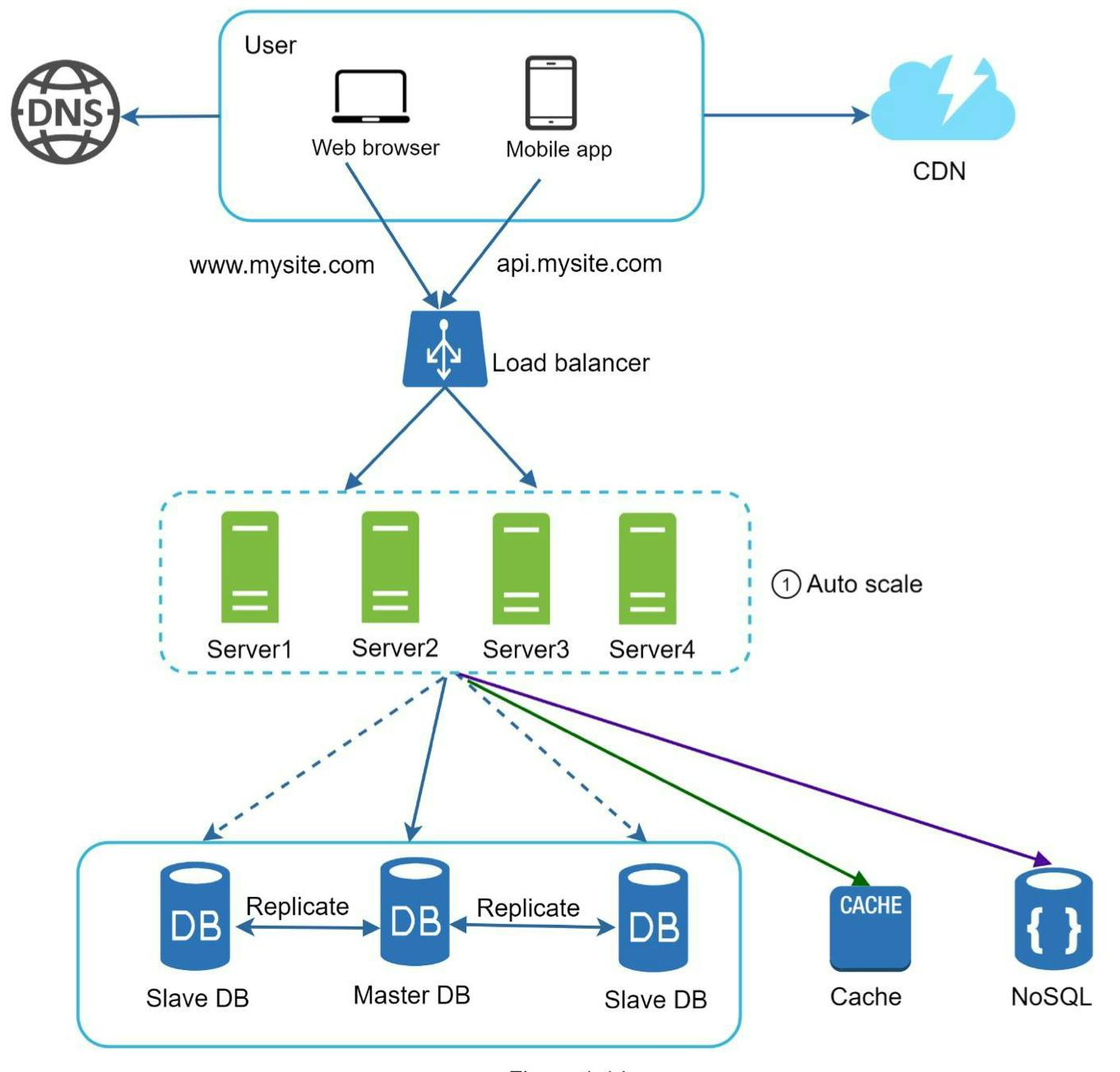
Việc có cache và CDN giúp mình giảm thời gian response nhưng khi ứng dụng scale lớn hơn, phục vụ nhiều người dùng ở các vị trí địa lý khác nhau thì có nhiều data center, mỗi data center có cache riêng sẽ đảm bảo user nhận được phản hồi nhanh nhất.
IX. Data centers
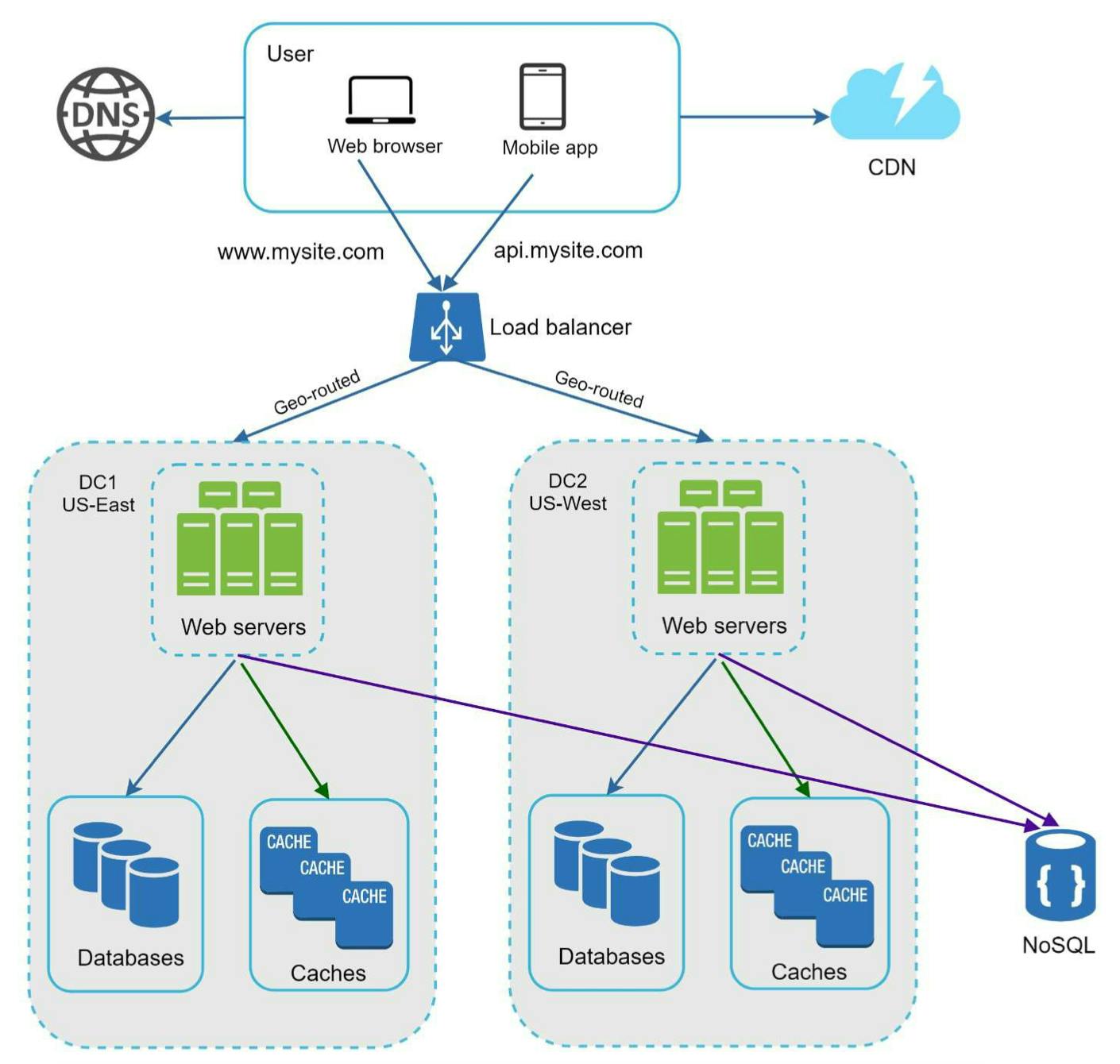
Request của user sẽ được geo-routed đến data center gần nhất (theo vị trí địa lý). Việc xây dựng multi-data center cũng có một số thách thức:
Traffice direction: trên lý thuyết các request phải được directed đến data center gần nhất. GeoCDN thực tế thường được dùng để làm việc nàynày.
Data sychronization: hiển nhiên là user từ các nơi cách xa nhau được access đến những data center khác nhau. Dữ liệu trên các data centers này có thể không được đồng bộ. Giải pháp thường được dùng là replicate data.
Test and deployment: khi có nhiều data center ở các location khác nhau, mình phải test app/mobile của mình với các vị trí địa lý khác nhau. Automated deployment tools thường được dùng để deploy các services trong tất cả data centers.
Ngoài ra, một số lời khuyên từ các lập trình viên đi trước là mình có thể decouple một số components trong hệ thống và scale chúng một cách độc lập. Khi đó, message queue là thứ được áp dụng rất nhiều trong các hệ thống phân tán để giải quyết bài toán này.
X. Message queue
Message queue có thể xem là một component đượcđược stored trong memory nhằm hỗ trợ các tác vụ bất đồng bộ (asychronous). Một kiến trúc cơ bản của message queue gồm producers/publishers, message queue và consumers/subscribers như hình minh họa dưới đây:

Xét một ví dụ thực tế là giả sử app của mình cần support cho tính năng photo customization bao gồm: crop ảnh, sharpening, blurring, etc. Những task này tùy vào kích thước, dung lượng ảnh mà thời gian thực hiện sẽ khác nhau.
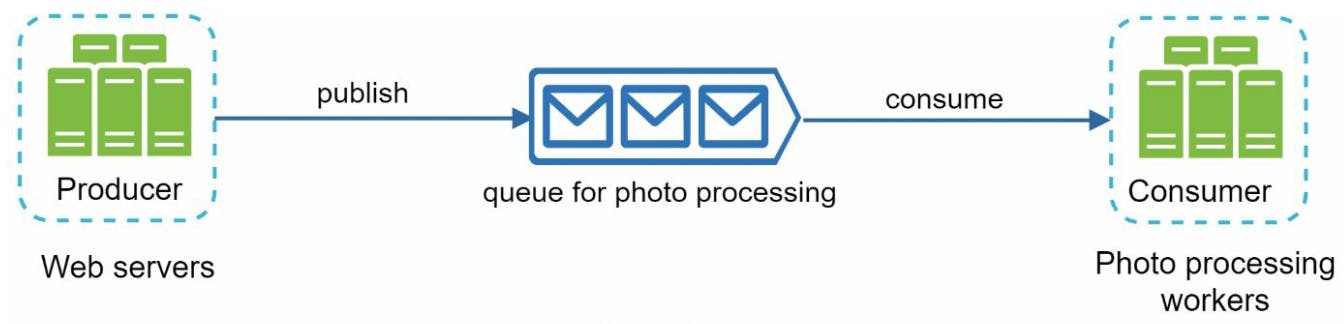
Web server trong trường hợp này đóng vai trò publisher publish photo processing job tới message queue. Photo processing worker nhận message từ message queue và xử lý các tác vụ customize photo, quá trình xử lý diễn ra bất đồng bộ trong hệ thống.
Hệ thống của mình sau khi có thêm message queue và logging, metrics sẽ như sau:
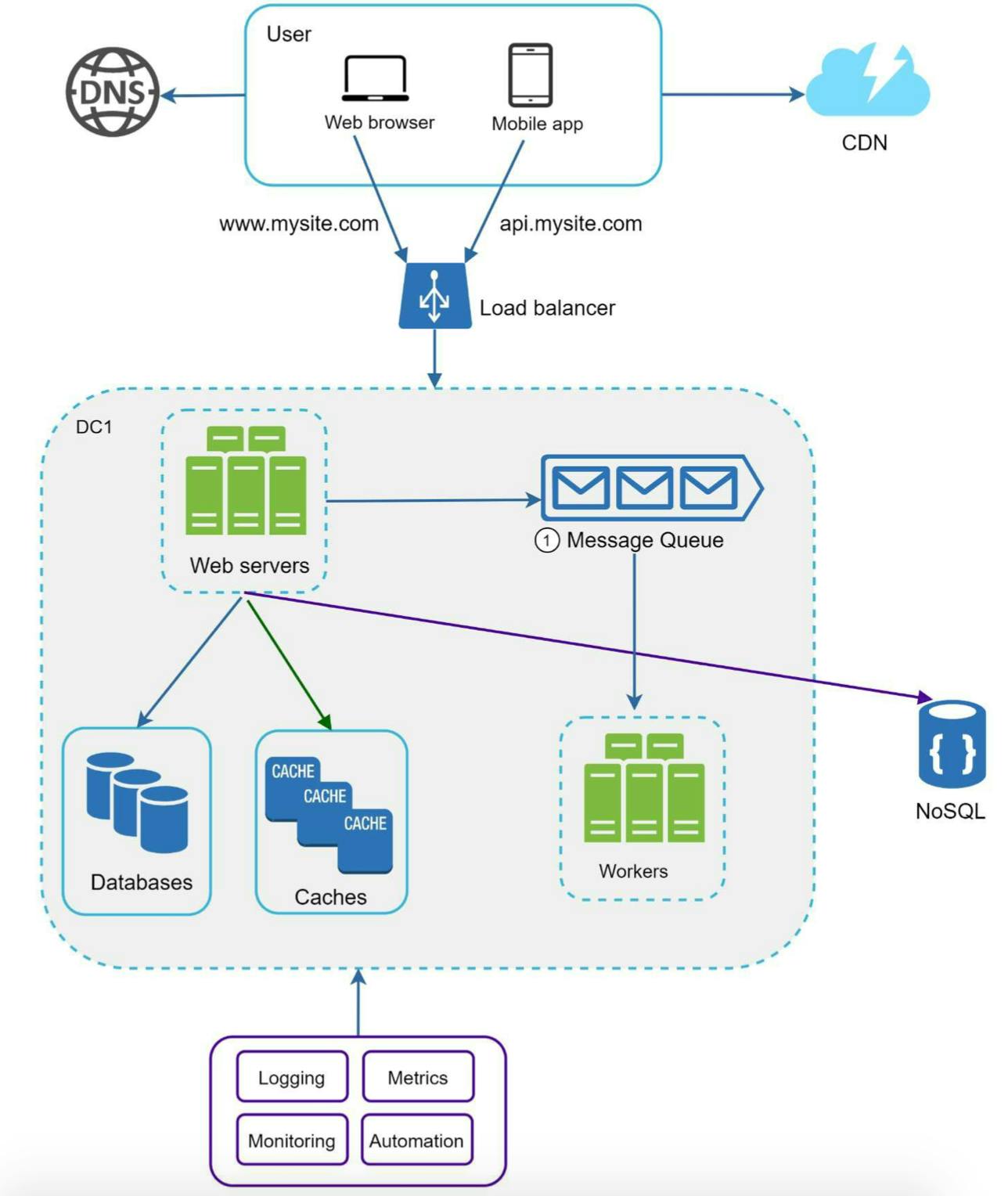
Mình đã có khá nhiều giải pháp để scaling web tier, bây giờ, mình tiếp tục tìm hiểu về scaling ở database tier.
XI. Database scaling
Cũng như web tier scaling, mình có horizontal scaling và vertical scaling cho database tier. Về vertical scaling là việc thêm RAM, tăng tốc độ CPU ... cho database server. Horizontal scaling (hay còn gọi là sharding) là việc mình add nhiều server vào server pool của database.
Hay nói cách khác, sharding là việc mình chia nhỏ một database lớn để dễ quản lý hơn. Mỗi shard đều có schema giống nhau nhưng data trong mỗi shard là khác nhau. Mỗi khi mình cần access data trong database, một hàm hash (hashing function) sẽ được dùng để xác định data mình cần đọc hoặc ghi nằm trên shard nào.
Ví dụ đơn giản của hàm hash là userid≡k(mod4). Khi đó k sẽ nhận các giá trị (0, 1, 2, 3) tương ứng với các shard store data đó.
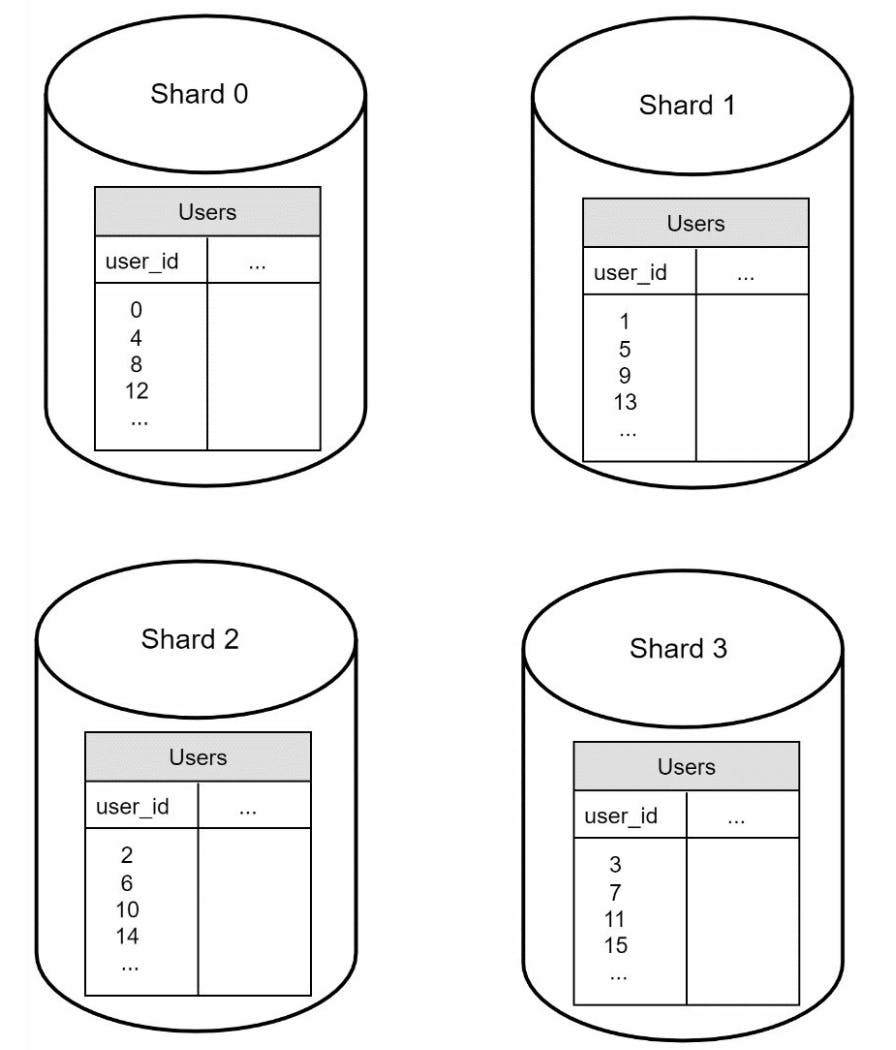
Điều quan trọng nhất khi implement sharding strategy là chọn sharding key. Ở ví dụ trên mình chọn user_id, thực tế mình có thể chọn một hoặc nhiều column để quyết định cách thức phân tán dữ liệu. Tuy nhiên cũng còn khá nhiều vấn đề để mình cân nhắc với việc sharding database:
Resharding data: việc resharding data cần thiết khi
Data lưu trữ trong mỗi shard hoặc một shard nào đó nhiều lên
Một hàm băm tất định (consistent hashing) là kỹ thuật thường được dùng trong trường hợp này
Celebrity problem: hay còn được gọi là hotspot key problem. Là trường hợp các data được lưu trong một shard nào đó được access nhiều lần (data của những người nổi tiếng chẳng hạn - lý do của tên gọi này). Vấn đề này thường gặp với các social application, các tài khoản nổi tiếng nếu được hash vào cùng một shard thì sẽ làm cho shard đó nguy cơ bị quá tải do việc truy vấn read/write diễn ra thường xuyên hơn.
Join and de-normalization: Khi data được sharded, mình sẽ khó sử dụng join operation. Giải pháp sử dụng ở đây là de-normalize database để các queries có thể thực hiện trong 1 bảng.
Trên đây là một số lý thuyết chung mình tìm hiểu được, còn nhiều vấn đề chưa đề cập đến như bảo mật, xác thực phân quyền, một số design patterns thường dùng, microservices, ... sẽ được nói đến các bài sau. Như vậy qua bài này mình đã rút ra được một số nhận xét:
Giữ cho web tier stateless
Build redundancy mỗi khi có thể
Cache data trước khi trả về client
Support multiple data centers
Host các static file lên CDN
Scale database tier bằng sharding
Chia nhỏ tier (ví dụ web tier) thành các services riêng biệt khi cần
Monitor hệ thống và sử dụng automation tools giúp việc logging và deploy được thuận tiện.